|
|
文章来源:NeurIPS 2022(在审)
原文链接:https://arxiv.org/pdf/2205.05832.pdf
<hr/>摘要
近年来, FLAT在中文NER方面取得了巨大的成功。FLAT通过构造汉字格来实现词汇增强,减轻了词边界模糊和词语义缺失带来的困难。在FLAT中,起始字符和结束字符的位置用于连接匹配的单词。但是,在处理较长的文本时,这种方法可能会匹配更多的单词,从而导致较长的输入序列。因此,它大大增加了self-attention模块的内存使用和计算成本。为了解决这个问题,本文提出了一种新的词增强方法InterFormer,该方法通过构造非平面汉字格有效地减少了计算量和内存占用。此外,本文以InterFormer为主体,实现了中文NER的NFLAT方法。NFLAT将词汇融合和上下文特征编码解耦,减少了不必要的“word-character”和“word-word”的attention计算。这一方法减少了大约50%的内存使用,可以使用更广泛的词汇或更大的batch-size进行训练。在几个著名的基准测试上获得的实验结果表明,该方法优于最先进的混合模型。
方法简介
与英文相比,中文的NER更具挑战性。首先,汉语的词界是模糊的,没有空格等分隔符来明确词的界限。
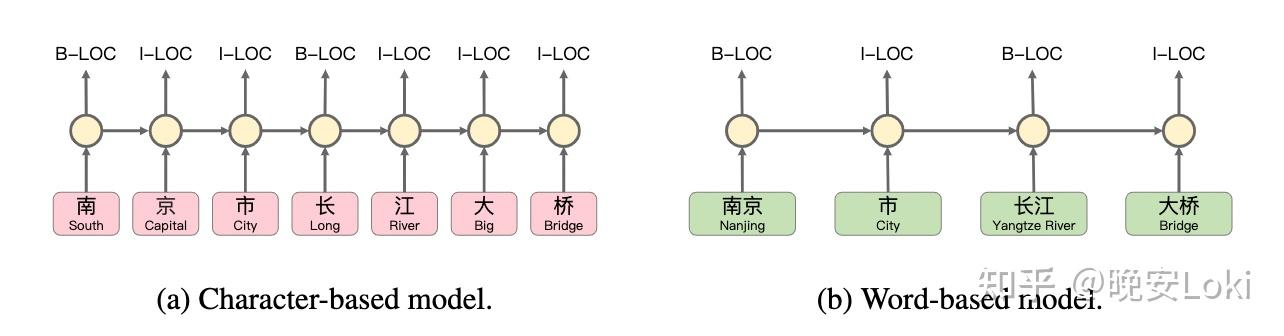
图1:不同粒度的中文NER模型,红色是字嵌入,绿色是词嵌入。
如果采用汉字级的NER模型(图1a),则会存在语义缺失和边界信息缺失的问题。另一方面,如果使用词语级模型(图1b),错误的分词也会降低性能。此外,中文还有更复杂的属性,如复杂组合、实体嵌套、长度不定和网络新词。此外,汉语不具有区分大小写和词根词缀的属性,缺乏大量语义信息的表达。因此,近年来,主流的中文NER方法都侧重于使用外部数据,如词汇信息、象形文字信息、语法信息和语义信息等来提高性能。FLAT是一种非常流行的词汇增强方法,可以有效提取实体边界和丰富的词汇语义。然而,传统的FLAT显著增加了计算和内存使用成本,并且在FLAT中使用大规模的词汇是非常困难的。为了缓解这些问题,本文提出了一种新颖而有效的词汇增强方法NFLAT。
本文提出了一种新的非平面格结构的InterFormer网络,它联合建模不同长度的字符和单词序列。
以InterFormer为主体,本文进一步为中文NER开发了一种非平面格词汇增强方法,即NFLAT。
背景
FLAT是与本文提出的方法最相关的研究。FLAT通过两种位置编码的平面格引入词汇信息,显著提高了中文NER的性能。然而,这种方法平均增加了超过40%的输入序列长度,导致了一些实际问题。使用较长的序列显著增加了自我注意力的记忆和计算成本,导致FLAT无法使用更大或更全面的词典,并且它对“word-character”和“word-word”的attention得分进行不必要地计算。
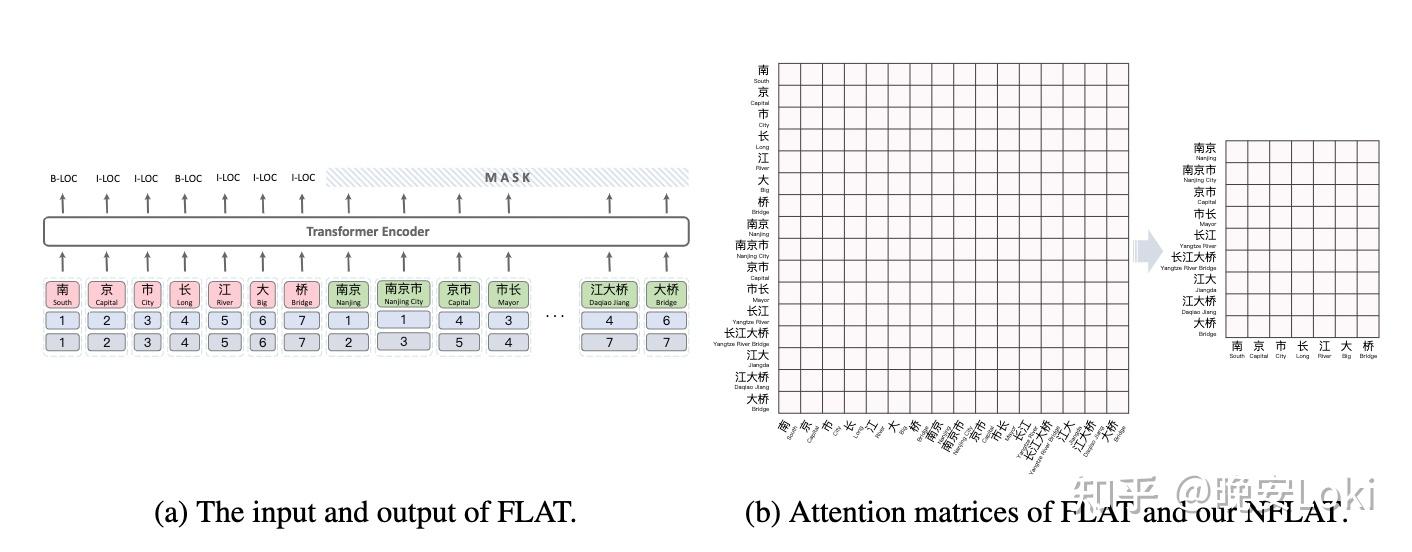
图2:FLAT及其attention矩阵
(a) FLAT的输入是由两个位置编码构成的平面晶格,红色的是character编码,绿色的是word编码。(b)当序列较长时,FLAT的自注意矩阵变大,而右边提出的InterFormer方法大大简化了attention矩阵。如图2a所示, FLAT通过引入两种位置编码,构建一组平面格作为模型的输入,对character和word进行建模。它解决了词边界模糊和词语义缺失的问题。然而,当处理较长的文本时,这种方法可能匹配更多的单词,导致较长的输入序列和更多的计算成本。因此,FLAT在处理长度超过200的句子时很困难。更重要的是,通过分析发现没有必要在自我注意中的“word-character”和“word-word”之间进行计算(图2b)。原因是包含全局信息的词表示在解码阶段会被mask(图2a)。
模型结构
对于中文的NER, NFLAT有三个主要阶段。第一阶段使用InterFormer融合词的边界和语义信息。第二阶段使用Transformer对上下文进行词汇信息编码。最后使用条件随机场(CRF)作为解码器来预测序列标签。NFLAT的整体架构如图3所示。
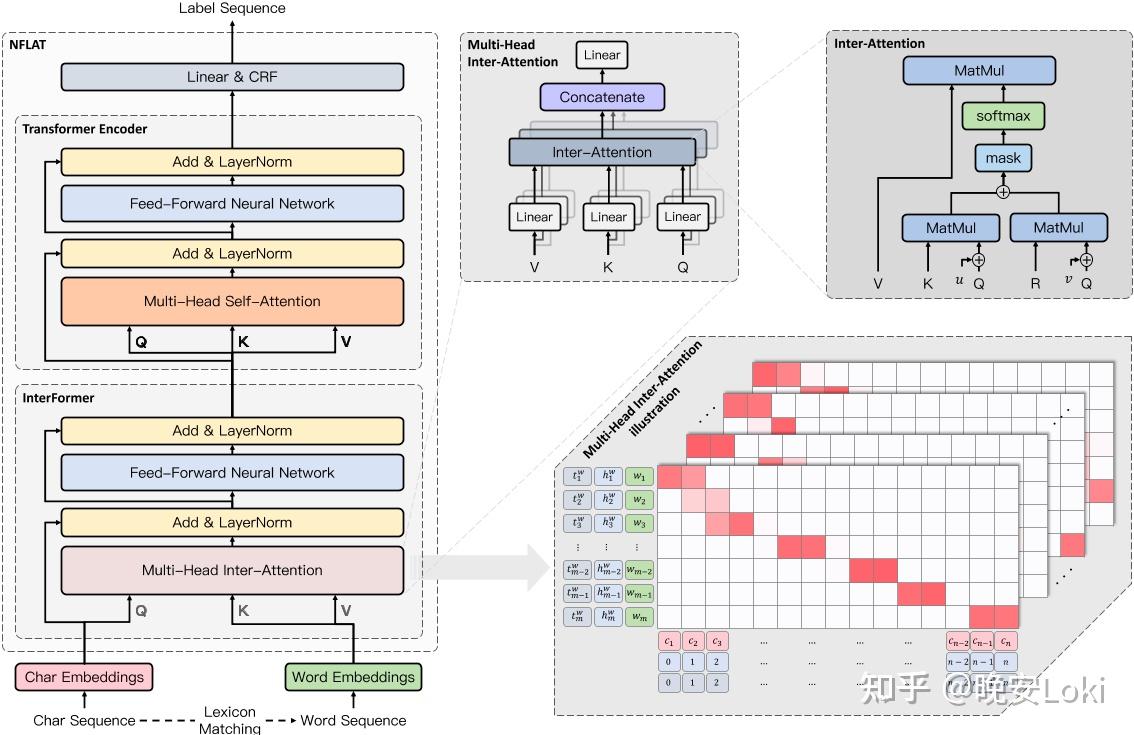
图3:NFLAT的整体架构
InterFormer
如图3所示,本文所提出的InterFormer方法其实就是Transformer Encoder的改进版,InterFormer包含一个多头inter-attention和一个前反馈神经网络FFN,目的是构建一个非平面格结构,可以同时对character和word两个不同长度的序列进行建模,让他们交互,从而获得融合了word边界和语义信息的character表征。
对Transformer Encoder的改进主要是:
attention中query/key/value不再同源,也就不再是self-attention,character序列作为query的输入,word序列作为key和value的输入。这样的话attention在character序列中每个字上的输出就是word序列中与这个字相关的word表征(value)的加权求和的结果。并且在word序列中加入了一个标记<non_word>,这样的话,如果character序列中的某个character与词序列没啥关系的时候,就不会强行加权求和。
Inter-Attention模块
中文character序列 C=\left\{ c_{1},c_{2},...,c_{n} \right\} ,和word序列 W=\left\{ w_{1},w_{2},...,w_{m} \right\} ,可以通过词典匹配得到。通过字符与单词特征嵌入的线性变换得到输入 Q,K,V :
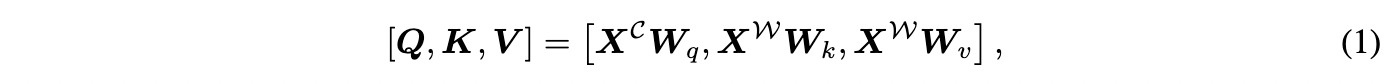
其中character和word序列的标记嵌入, X^{C}=\left\{ x_{c1},x_{c2},...,x_{cn} \right\} 和 X^{W}=\left\{ x_{w1},x_{w2},...,x_{wm} \right\} ,都是通过一个词嵌入查找表得到的。每个 W 都是一个可学习的参数。本文中使用相互注意来融合词汇信息:
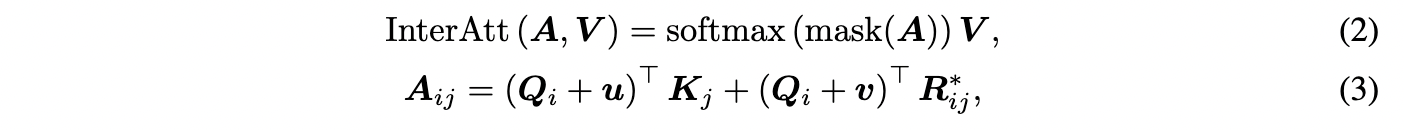
其中 1\leq i\leq n ,1\leq j\leq m 。 u,v 是可学习的参数。mask(A)是字和词之间的attention得分掩码,使padding部分的权重在softmax后结果接近于0。
相对距离的表征R_{ij}^{\ast} 的计算方法与FLAT类似,但也做了一些改动,FLAT中计算了四种位置距离表征:head-head, head-tail, tail-head, tail-tail,但这里只有两种位置距离:character head - word head (h_{i}^{c}-h_{j}^{w})和 character tail - word tail (t_{i}^{c}-t_{j}^{w})。将这两个距离拼接后作一个非线性变换,得到x_i和x_j的位置编码向量R_{ij}:
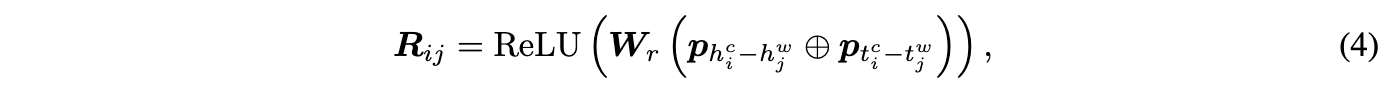
其中, W_{r} 是一个可学习参数, h 和 t 是单词在输入文本中的第一个和最后一个字符的位置号,上标 c 和 w 分别表示汉字和词语。 h_{i}^{c}-h_{j}^{w} 表示第 i 个汉字和第 j 个词语的头部位置偏移量, t_{i}^{c}-t_{j}^{w} 表示第i个character和第j个word的尾部位置偏移量,即相对位置。位置编码 p 采用正余弦函数,生成方法如下:
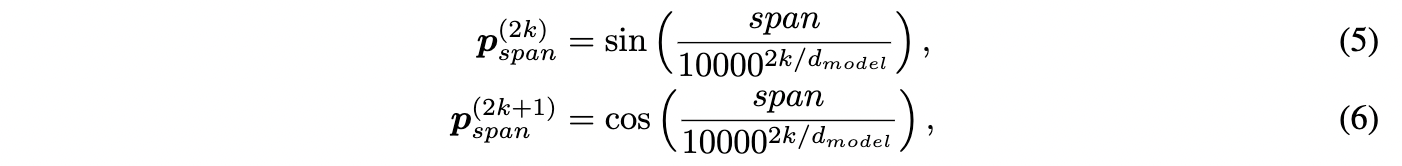
其中span表示 h_{i}^{c}-h_{j}^{w} 和 t_{i}^{c}-t_{j}^{w} , k 表示第 k 维, d_{model} 为hidden size。
Multi-Head Inter-Attention
在初步实验中,作者发现多头的互注意能更有效地融合词汇信息,不同多头信息具有互补作用。多头间注意计算如下:
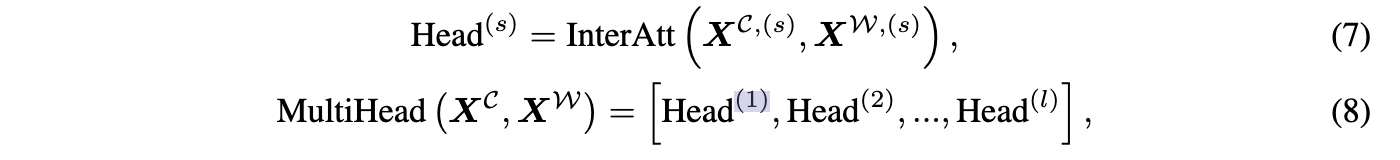
其中 l 为inter-attention头的个数,Head(s)为第s个注意间头在字符和词向量子空间上的输出结果。 X^{C,(s)} 和 X^{W,(s)} 是字和词在其子空间中的向量表示。
Feed-Forward Neural Network
本文的FFN使用两个全连接层,实现了互注意编码器的前馈神经网络子模块:
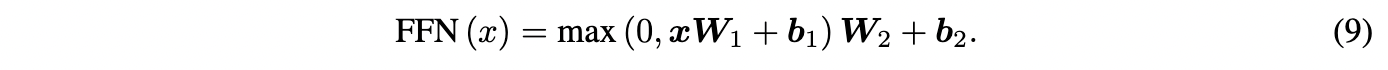
此外,作者还在上述两个子模块中使用了残差连接和层归一化,以加快网络训练的收敛速度,防止梯度消失问题:
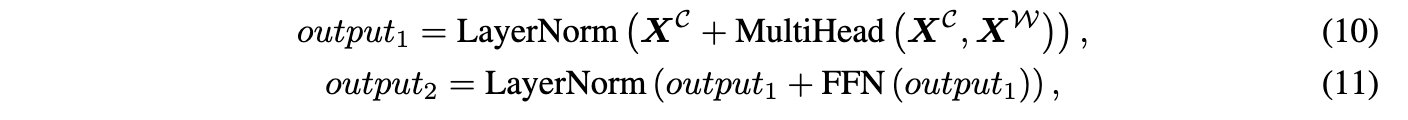
其中output1和output2为上述两个子模块的输出。
通过上面的这一系列操作,就获得了“融合了word边界和语义信息的character表征”。
Transformer Encoder
在InterFormer后,字符表征与词典信息融合。然后使用Transformer编码器对上下文信息进行编码。在此之后,使用线性层将输出投影到标签空间,并使用CRF进行解码。
实验结果
本文使用F1评分、精度和召回率来评估所提出的NFLAT方法,并比较了几个“字-词”混合模型,还研究了NFLAT的复杂性和InterFormer的灵活性,并比较了其他词汇和使用预训练模型的效果。
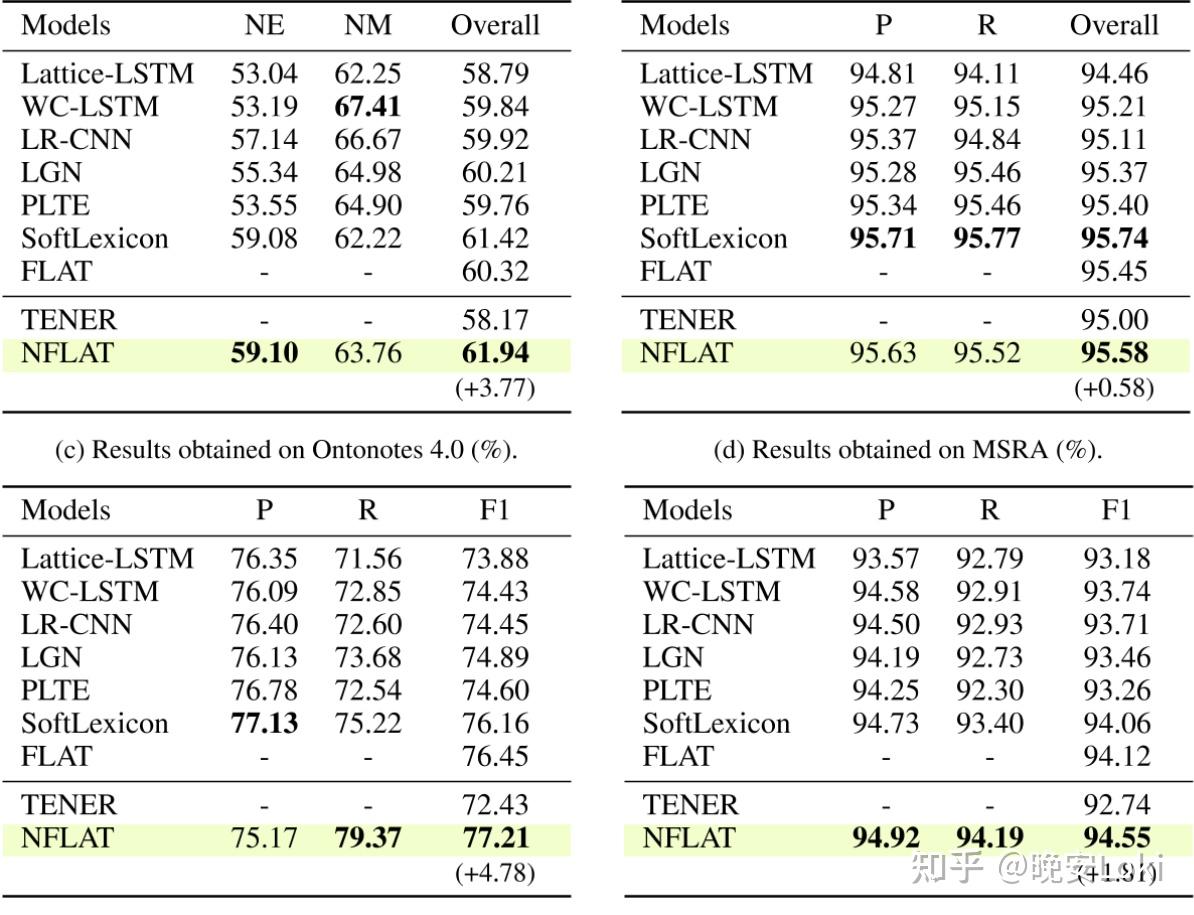
表1:实验结果
通过表1可以看到,NFLAT在4个数据集上效果都还挺好的,达到了SOTA。
时间复杂度
只考虑attention模块。NFLAT包括字和词的inter-attention O(nm) 和上下文的self-attention O(n^{2}) ,因此总复杂度为 O((n+m)n) 。FLAT方法的attention复杂度为 O((n+m)^{2}) 。随着句子长度 n 的增加,匹配词序列的大小 m 也必然增加,使得计算复杂度难以估计。由下图可以看到,当句子长度小于400时,FLAT和NFLAT的表现相似。之后,随着句子长度的增加,NFLAT的速度会比FLAT快。当句子长度超过700时,由于占用内存过多,FLAT无法在GPU上运行。
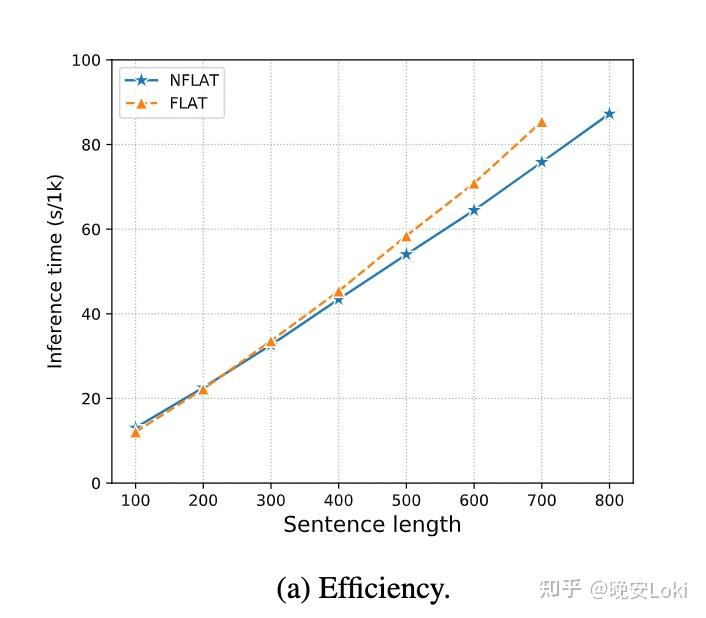
运行时间对比
空间复杂度
在FLAT中,self-attention计算需要两个 (n+m) 矩阵,因此空间复杂度为O((n+m)^{2})。NFLAT中self-attention和inter-attention的空间复杂度分别为O(n^{2})和O(nm)。 n 越大, m 也越大。因此NFLAT的内存使用量几乎是FLAT的一半。如图所示,随着句子长度的增加,FLAT占用越来越多的内存。另一方面,NFLAT具有更稳定的内存占用率并且在句子长度超过1000后仍能正常工作,在训练阶段可以提高设备的利用率。
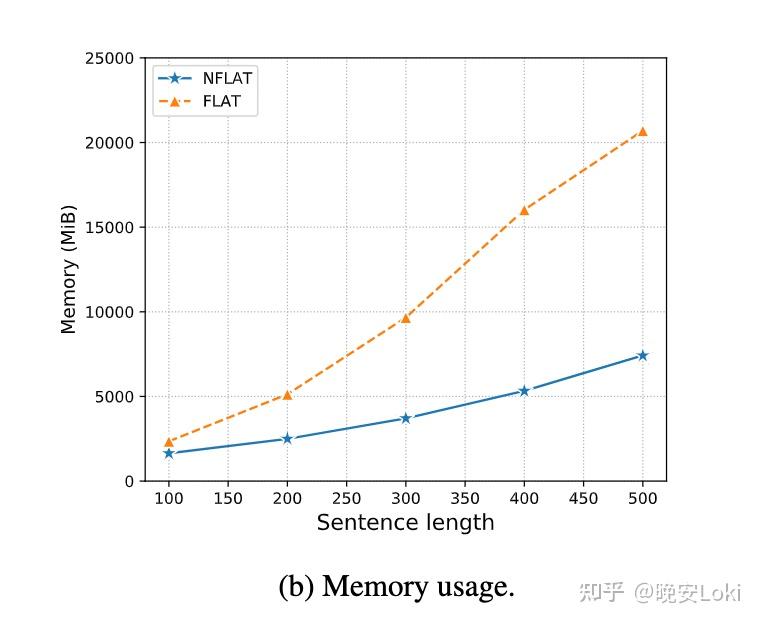
内存占用对比
总结
本文提出了一种新的非平面格InterFormer模块,以及NFLAT体系结构,用于中文NER的词汇增强。NFLAT对FLAT进行了解耦,将中文NER分为词汇融合和上下文编码两个阶段,具有明显的性能优势和效率。InterFormer可以灵活地关联两个不定长度序列,实现了中文NER的显著性能提升。 |
|



 发表于 2022-9-21 06:25:07
发表于 2022-9-21 06:25:07